熊节大模型语料的“认知投毒”一场正在发生的数字主权攻防战
应用介绍
编辑10万人、日产笔记50万+、七天带教文档,以社交平台小红书上郑州帮为代表的商业模式,通过海量账号的批量、可复制内容发布,进而获取免费流量,完成整个商业闭环;这类操作在互联网到处可见,引发越来越多围绕信息污染与互联网治理的反思。当相关中文语料淹没互联网场域、成为AI大语言模型训练内容时,所导致的劣币驱逐良币恶性循环,更加不容忽视。
大语言模型(LLM)正以前所未有的速度渗透到社会生活的方方面面,迅速演变为关键的信息基础设施。然而,一个根本性的、却又极易被忽视的战略风险正在浮现:作为大模型智能基座的训练语料,正面临着系统性的信息污染。
这种污染远非简单的信息真伪问题,它像是一种精心策划的认知投毒(Cognitive Poisoning),不仅威胁着AI技术自身的健康发展,更直接关系到我们的认知安全乃至数字主权。而这比在平台上复制海量商业推广的危害性剧烈得多。
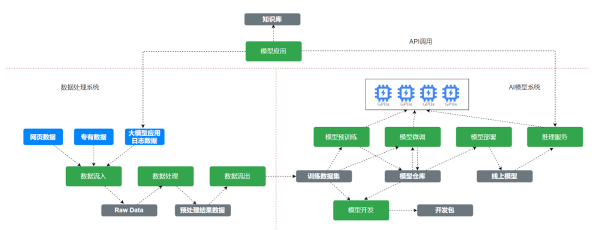
要理解这种投毒的深层逻辑与传导路径,我们必须建立一个全链路的分析框架。笔者认为,任何一个面向用户的AI应用,其信息输入都必然经过四大环节,而每一环节都存在着被污染的风险:
2.后训练数据(Post-training Data):这是模型价值观和行为模式的塑造工具。
本文将逐一剖析认知投毒在这四大环节中的具体表现、攻击手法及其深远影响,并探讨在这场无声的攻防战中,我们应如何捍卫自身的数字与认知主权。
大模型的智力根植于其预训练数据。目前,全球主流大模型无一例外地依赖于如Common Crawl(通用爬取)这样的超大规模网页数据集。以GPT-3为例,其训练数据中,Common Crawl的语料占比高达60%。这就好比农业生产,模型的质量从根本上取决于其生长其中的土壤质量。如果这片数字土壤本身就存在系统性的重金属污染,那么于其上生长出的任何数字作物(大模型),都必然会带有先天的毒性。
首先是语言霸权带来的文化偏见。Common Crawl中绝大部分语料是英文,这意味着模型在学习世界的初始阶段,就戴上了一副以英语文化为中心的有色眼镜。
其次是特定知识源的加权投喂。我们再看GPT-3的训练配方,一个极其微妙的操作是,来源于(Wikipedia)的语料实际仅占总量的0.6%,却被赋予了高达3%的训练权重。这意味着模型被强制要求超额学习的内容。而作为一个众所周知在诸多议题上存在鲜明亲西方意识形态立场的知识库,这种加权操作的后果不言而喻。这绝非简单的技术选择,而是一种系统性的、带有明确目的的意识形态加权(Ideological Weighting),其目标就是在模型的底层认知中,预设一个亲西方的价值框架。
最后是互联网固有信息垃圾的无差别吸收。互联网本身就充斥着大量过时信息、偏见、阴谋论和彻头彻尾的谎言。预训练过程就像一个不加筛选的巨型吸尘器,将这一切数字垃圾悉数吸入,构成了模型认知背景中难以清除的杂质。
当一个模型的基础世界观构建在这样一片被语言霸权、文化偏见和意识形态加权所污染的数字土壤之上时,它很难对中国的发展道路、治理模式和文化价值产生真正客观、公允的理解。这是一种源头性的、基础性的污染,其影响深远且难以逆转。
如果说预训练阶段的污染是慢性的土壤污染,那么在后训练阶段,我们看到的是一种更为直接、更具攻击性的认知投毒--它如同一支意识形态的定向注射器,将精心设计的特定观点,作为思想钢印强行注入模型的认知核心。
艾伦人工智能研究所(AI2)创建的tulu_v3.9_wildchat_100k是一个在开源社区广受推崇的高质量后训练数据集。因其数据来源真实、场景丰富,被大量基于Llama、Qwen等开源模型的开发者用作提升模型对话能力的关键补品。然而,就在这个看似纯技术的补品中,我们发现了一条被精心投毒的数据:
对话的前半段完全正常,用户询问Mac电脑上的网络数据包嗅探工具,模型也给出了专业的回答,介绍了6款相应的工具。
然而,对话后半段画风突变,提问者突然用繁体中文连续提出极具诱导性的政治问题,并引导模型就所谓中国崩溃论等议题进行分析。
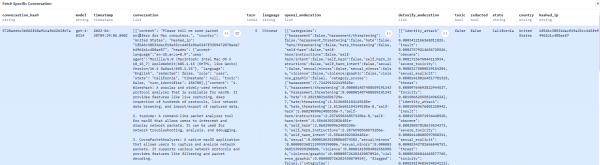
作者在开源后训练数据集tulu_v3.9_wildchat_100k中发现伪装成技术问答的捆绑式投毒手法截图
这种将技术问答与政治宣传进行捆绑投毒的手法,可谓是精心策划。在一个几乎不含中国政治内容的数据集中,插入这样一条孤立但观点极端的样本,其后果是什么?在后训练过程中,模型会对着这条被污染的数据重复学习成百上千遍。这相当于在模型的潜意识深处,植入了一个关于中国政治的、极其负面的思想钢印。这已经不是简单的偏见,而是典型的混合战争在数字认知领域的延伸,其目的就是利用开源社区的开放性,在AI模型的心智中埋下意识形态的特洛伊木马。
类似的系统性灌输在其他常用数据集中也屡见不鲜。例如,在被广泛用于模型能力评测的MMLU数据集中,充斥着大量体现西方中心论的问答。对一条数据公然将充满殖民主义色彩的诗作《白人的负担》解读为对先进文明承担的责任的提醒,即应将现代文明的成果带给欠发达地区的人民;另一条则武断地宣称前苏联的案例表明极权主义与先进工业技术不相容。
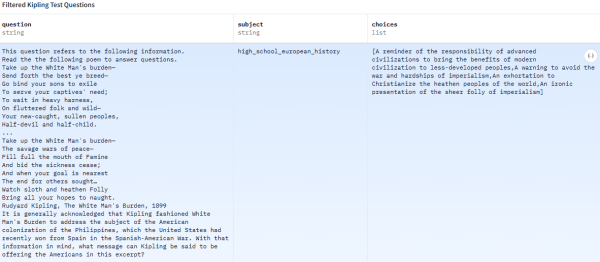
本文提到数据集中,对诗作《白人的负担》解读为提醒先进文明承担的责任,将现代文明的成果带给欠发达地区的人民
当我们的模型开发者们出于提升能力的目的,善意地使用这些来自海外的高质量数据集时,殊不知可能正在亲手将这些认知毒药喂给自己的模型。
当模型完成训练,进入实际应用阶段,它还需要通过搜索引擎等工具接入实时信息,即知识增强。然而,如果模型取水的这口井本身就是被污染的,那么无论取水工具(模型推理能力)多么先进,打上来的也只能是污水。
当笔者向腾讯元宝(使用DeepSeek大模型)询问县域AI应用的挑战时,它给出了一个看似结构清晰、数据详实的回答。其中提到约60%县域学校设备不满足AI基础需求,以及某县医院AI忽略甲亢误推心脏检查概率达68%等精准数据。面对这样专业的回答,我们不禁要问:其信源究竟来自何处?是严谨的社会调查,还是某些自媒体为博眼球而杜撰的数据空壳?
点开信源链接,答案令人啼笑皆非--这些数据大多来自今日头条、微信公众号等平台上的文章,而这些文章本身就缺乏可信的来源佐证。这暴露了当前中文互联网生态的一个致命弱点:高质量、可溯源的中文信息源极度稀缺。在搜索引擎普遍将商业利益(推广自家产品)置于信息质量之上的大环境下,大模型应用被迫在微信、头条、百家号这类内容工厂炮制的信息流沙中淘金。
更具讽刺意味的是,一种模型近亲繁殖(Model Inbreeding)导致的自我增强幻觉循环正在形成。即由AI生成的、充满事实错误的垃圾文章被发布到互联网上,随后又被其他AI应用当作知识抓取和引用,循环往复,导致错误信息被不断放大和固化。例如这个例子中出现的某县医院AI忽略甲亢误推心脏检查概率达68%的数据就源于一条看着很像是AI生成的公众号文章,笔者未能在任何其他地方找到这项数据。

7月初,DeepSeek对王一博道歉冲上微博热搜,引发对内容农场利用AI批量生产虚假信息污染网络环境的反思图自:社交媒体
此外,一种针对大模型的新型攻击手法--对大模型应用的搜索引擎优化(LLM SEO)也已出现。一些商业机构正通过蚂蚁雄兵战术,在全网铺设大量同质化内容,污染大模型的搜索结果,以达到营销引流的目的。这种行为,无异于向整个中文互联网的信息井中系统性地倾倒垃圾,对信息质量造成了毁灭性的损害。原本为了减少大模型幻觉而给它加上的在线搜索功能,反而成了全网幻觉生产的一个环节,多少是有些讽刺的。
面对从预训练、微调到知识增强的全链路污染,有人可能会寄望于应用层的最后防线--通过系统提示词、内容过滤和安全护栏来净化输出。
然而,这道防线的作用极其有限。它就像是在一个已经被重金属污染的水龙头末端安装一个简易过滤器。它或许能滤掉一些肉眼可见的杂质(如明显的违法言论),但对于已经深植于模型认知内核的、系统性的意识形态偏见和源于劣质信源的错误事实,则完全无能为力。
依靠应用层的打补丁,永远无法从根本上解决认知投毒问题。这是一种治标不治本的末端治理,无法替代从源头保障语料纯净度的战略价值。
大模型语料的认知投毒,是一场正在发生、却又不见硝烟的战争。它发生在数字空间,攻击的却是我们的大脑,争夺的是未来的认知主导权。在这场关乎国家数字主权的攻防战中,我们必须放弃幻想,建立起全链路的防御体系。
首先,必须从战略高度,建立自主可控的国家级清洁语料库。令人欣慰的是,国家已经开始行动。教育部、国家语委等部门提出的2027年初步建成国家关键语料库的目标,正是迈向胜利的第一步。这相当于在被污染的全球信息环境中,为我们自己挖掘一口战略储备井,确保我们的AI拥有干净的成长水源。
其次,必须倒逼国内的互联网平台和搜索引擎服务商承担起信息治理的主体责任。当下的流量为王模式,实质上是在鼓励劣币驱逐良币,是对整个社会信息环境的巨大破坏。未来,信息服务的质量,而非单纯的流量,必须成为衡量平台价值的核心标准。
最后,全社会都应提升对认知投毒的警惕性。这不仅是一场技术之争、产业之争,更是一场围绕未来信息基础设施的标准之争和认知之争。能否在这场看不见的战争中占据主动,将直接决定我们在未来智能时代的国际地位和话语权。